
Every few decades or so, a new craze in technology will come along. In the 1990s, the birth of the internet. In the early 2000s, the infancy of social media. Now, in the 2020s, we appear to be staring down prospect of the creation of artificial intelligence.
Regardless of any moral, social or wider arguments about the concept of machine learning, it is undeniably fascinating technology. The idea that a machine can imitate the function of a living, breathing individual is so far removed from our classical experience of technology that it is difficult to not become impressed. This article however will not be celebrating or showcasing the abilities of AI. In fact, by the end of this article, I hope to have convinced you that, not only is AI nowhere near as complex or intricate as it initially appears, but that, really, it functions based on incredibly simple concepts. Of course, just because something is simple does not mean it is not an achievement, nor that it is incapable. On the contrary, the best inventions originate from simple ideas which a seed of potential. Despite all this, I have made due simplifications where necessary to avoid delving into complex mathematical theories where possible.
With all that said, let’s dive in to the world of machine learning.
The Origins of Machine Learning
To begin with, it feel it may be beneficial to go all the way back to the beginning.
Machine learning is a concept which has been discussed in Science Fiction since the time of Jules Verne. The basic idea behind this concept is that a machine can improve its own instructions based on learning from wide experience. Under normal circumstances, computers are limited machines; they may only follow their own set of instructions (also known as their “programming” or “coding”). For this reason, computers are rigidly defined in terms of their input and output. Anything which they were not explicitly designed to handle and, most crucially, instructed on how to handle, will simply no go understood. This means that processes such as human language, which are wide, varying and often ambiguous, are almost impossible to instruct a computer on how to understand. The solution to this is machine learning. This learning is designed to occur in a similar way to natural learning in human beings, as modelling after the natural process of learning gives us a solid starting point as to re-invent the processes of nature using electronics. The basic idea is that, if a computer program can be created which produces other computer programs, a computer could be taught the art of self-improvement.
This may sound very abstract and hypothetical, so let’s use an analogy to understand this further. Imagine I gave you a set of words, say:
cat
dog
mouse
house
And I asked you to put them in “the right” order. What is “the right” order? Well, that is for you to learn through your training. Given no extra information, your only real option as to what to do is to make a wild guess. The order you end up with may be entirely random, it may be alphabetical, reverse alphabetical or any other selection of wild and unnecessary orderings. What matters is that you are wrong. To start with, you have no extra information regarding the required method of ordering, but after you have given the wrong answer, imagine that I gave you the correct order:
mouse
cat
house
dog
Is the required order now evident? Possibly, but also possibly not. Now imagine that many, many examples were given. For each one, you are given one attempt at the correct order. If correct, you are told it is correct. If incorrect, you are corrected. Eventually, when given enough data to extrapolate from, it is natural that you will spot at least some pattern (in this case the colours of the rainbow).
Almost the exact same process is undergone by the computer when going through the process of machine learning. The computer is given a large set of data (known as “training data”) and it attempts to spot patterns as a result. This may seem like a flimsy system for learning, but, in reality, most of learning is built on top of the spotting of patterns. When learning to read, the specific patterns of letters which make up words will eventually be pressed upon your mind such that you know certain words and can immediately pronounce others. Musicians eventually learn the patterns of music such that they may be able to extrapolate and guess what the next step of the music will be. It just so happens that mathematicians and computer scientists have succeeded in building mathematical models which allow the computer to perform the process of “learning” through the mere process of finding the minimum of an equation.
One key point that I would like to impress upon the reader at this moment is the diminishing nature of this presentation of the “learning” which the computer undergoes. It still has to be spoonfed answers and everything it produces is a mere derivative work of such answers. The computer never really does any “thinking” of its own; instead, it is only rigidly following its training the way computers always have done. The difference in this case from the nature of traditional software is that the vastness of the quantity of information from training allows the automatically generated instructions that fit such a wide variety of situations that the computer can appear alive.
The Computerized Brain
The process which I have described so far is a high-level overview of how the process of machine learning works, but I have not as yet described the actual structure of the programs which do the work themselves. This is because this structure is a topic in of itself.
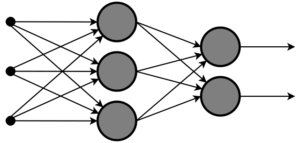
When designing the mechanism which computers use to “learn”, engineers took inspiration from the counterpart mechanism in nature: the brain. Essentially, a model is constructed known as a “neural network”. This maps closely to the structure of the brain, in that it is a large set of “neurons” which may fire or note fire, and which may fire with different strengths. This network of neurons are connected together using “pathways”. In this way, a graph-like structure of interconnected nodes and connections can be created. Then, the individual “activation function” of each neuron may be adjusted to transform some input into some output. These inputs from the user (for example, a prompt or the image data for an image) are then fed into the very first layer of “neurons” and work their way through each of the pathways being transformed into outputs.
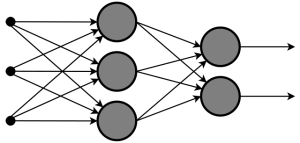
Above is shown an example of one such network. In this example, there are two outputs from three inputs. There are two layers of “neurons”, one layer containing three nodes and one containing two. The arrows between them are these pathways.
The way that data is processes is deceptively simple: every connection has an associated numeric value. This value is fed along the connections directly into each neuron. Each neuron has an associated value at which it is activated (and by how much when it is activated). This is called its “weight”. Each connection also has an associated value which it either adds or subtracts to the value passed along its path. This is called its “bias”. The collection of weights and biases are what entirely define the behaviour of the network, and are also what are changed during training. All the training program needs to do is change these weights and biases in such a way that the network can detect the patterns in input data and provide useful output.
In other words, all the “AIs” consist of are an extremely large set of numbers and connections between them. Personally, I find it amazing that such a basic concept can be used to create such complex machinery.
Training
On Seneca Learning, there is a useful little feature which will automatically mark answers to example exam questions based on an inputted mark scheme. This involves no human intervention at all and is powered entirely by machine learning. In fact, this is an almost perfect application of machine learning. There is a lot of data which can be used to train the algorithm and there are defined goals for success and failure. In this final section, I hope to give a shallow insight into how the “learning” part of “machine learning” actually takes place.
Machine learning works best when we are attempting to teach a computer to perform a task which humans are very good at, but not very good at expressing our methods to the machine. After all, the process of computer programming is expressing with sufficiently low ambiguity what task we wish the computer to perform. It will then perform this task exactly as instructed. The issue with this is, of course, that if our instructions are faulty or, more crucially, we don’t know what the instructions should be, we cannot express them. Effectively, all the mechanisms described above are in place such that the computer may infer the instructions we wish it to perform implicitly.
So, how do we go about “teaching” the computer in such a way. The process of “teaching” the computer to perform a task is known as training. The basic structure is as follows:
- The ML model is given some specific input (for example, a prompt text or an image of handwriting)
- The model provides what it thinks ought to be good output
- The human will then decide if this is acceptable or not, and provide an answer as to what the correct one should be
A good analogy for this process would be finding the center of a maze with a hidden pattern in the correct path to take. Each time you come to a fork in the path, you decide which way is most likely. If this is not the best path to take, you are told to turn back and instructed to go the correct way. For the purposes of the analogy, imagine that an electric shock or other negative feedback mechanism encourages learning to take place for an incorrect answer. The more times you are wrong, the better chance you have of learning why and being correct the next time. This is the same principle as was described in the first section. Eventually, you will need no (or very few) corrections at all.
Mathematically, this is modeled as the minimization of some mathematical function which represents what the machine has deduced so far about the mapping between inputs and outputs. The input data (prompt, image, etc.) are provided as parameters and the machine will find what output minimizes this function. For instance, if we asked the machine to find which digit most closely resembles a handwritten one, this function may some sort of representation of the “distance” between this character and another. Thus, the output which minimizes this function would be the expected output.
However, the most important concept to remember is that, after each iteration of training, the ML model’s internal state (how the model “thinks”) will have been adjusted. So, with more training come better results, as one may expect. Although more training does result in theoretically improved results, one pitfall in this method is the presence of what are known as “local minima”. In mathematics, there are things known as “local” and “global” extrema. The “local” extrema is the highest or lowest point which is closest to your current position. The “global” extrema, on the other hand, is that which is the highest or lowest possible. Take the example below for instance. If we find the local extrema for the point highlighted in blue, we will find the rightmost one. However, the leftmost extrema is lower. Hence, the rightmost is only local, whereas the leftmost is global.

When minimizing the function, as mentioned earlier, it is possible to be come “stuck” in a local minima. This leads to the algorithm adopting an inefficient or unwanted solution to the problem at hand. This is why it is often very difficult to get an ML model to “forget” unwanted information or to undo bad training, for instance.
If mathematics doesn’t serve you very well visually, imagine trying to find the lowest point on a mountain by rolling a ball down from the peak. You may roll straight down to the bottom, as you would expect. Or, the mountain may dip and climb back again higher than the ball started, before finally rolling back to the ground. For the curve in the image above, imagine rolling a ball down from the blue dot. It would become stuck in the local minima on the right hand side. This is exactly what happens for the function being minimized. There is no motivation to climb back up the other side, as it appears that we are climbing away from our objective as we have already struck gold at this minima we have found.
Now, the undertaking of training itself is often a rather tedious process, which is why it is much better if you can get users to do it for you. I mentioned the Seneca example earlier as Seneca always asks you to self-mark and compare with the output from their “AI marker”. Why do they do this? So that they can re-train based on new inputs from the user, just as was mentioned as the mechanism earlier. Anybody who has used the web for an extended period of time will have come across Re-Captcha, a Google project which is designed to cut down on botting and spam. Little did most users know, however, that only around half of the questions you were asked were for bot prevention. The other half were to train the model which marks your answers after you complete it. All Google needs to do is ask you some questions which are easy for humans to answer (such as “does this picture contain a bicycle”) and then average over the answers. Obviously, some humans will get the answer wrong, but these people can be eliminated by taking an average over all participants. Then, simply shuffle the questions so that it is difficult to tell which actually affect the test and people will be forced to answer honestly. Based on the average response, we can provide feedback to the computer and improve future captcha suggestions and answers.
Summary
Throughout this article, I have deliberately attempted to express to the reader how diminishing the technology of machine learning sounds when laid out in simple terms. This is partly due to omissions for the sake of simplicity, but is also due to the fact that machine learning is very often blown out of proportion by the media and companies with something to gain from its reputation. While it is true that this technology may allow us to solve problems we previously couldn’t, questions of if such technology is “sentient” or “living” or not are made fairly plain when explored at even a shallow depth beneath the surface level. Machine learning is good at spotting patterns. Humans detect other living things based on patterns. Ergo, machine learning is good at pretending to be a living thing. There are good reasons why many AI text bots reply with hilariously cartoonish representations of AIs when prompted for their “plans for the future” or when asked if they are evil; the data used to train them was over half a century of science fiction predicated almost entirely upon these cartoon villain AI models.
Of course, the question is then raised as to if something which is sufficiently good at pretending to be alive as to be indistinguishable ought to be treated as though it were alive. Or, perhaps in doing the pretending, in some way it has become alive. To this, I would reply that it does not matter as much the fact that decisions which appear human-like are being made by AI. Rather, it matters the manner in which these decisions are being made. Do we truly believe that a large bundle of transistors embedded in a silicon wafer may become alive simply because we throw large enough amounts of data at it? Perhaps not when written out so plainly.
Of course, this is partly down to my own personal opinion, but the jury is still out on this particular question. Is there something sacred about natural life which sets it apart from something artificially created by humans? After all, science today is no closer to explaining the baffling reality that is conscious experience to where it was in its infancy. It appears that some questions must go unanswered. All I can leave the reader with is the facts as I understand them. These are the basic principles as to how machine learning works. All other conclusions may stem from there.